# 聚集管理
聚集管理是指在模型的性能优化 > 聚集中创建并管理其对应的聚集表,当模型的数据量较大、维度较多而分组查询的维度较少时,可以通过聚集表来有效提升查询效率。
通常,你可以直接使用加工来生成一个聚集模型,然后基于该聚集模型再制作应用,这种做法需要提前分析清楚维度分组查询需求、规划好聚集模型。比较适合于前期需求做的非常好,模型规划很清晰的情况。
与此不同的是,聚集管理支持聚集导航,允许你只需使用原始模型制作应用,系统根据查询需求智能选择聚集表替代原表执行查询,所以你可以在应用制作完成后再考虑聚集表的优化,同时也不会带来任何应用修改工作。
# 新建聚集
在模型管理的性能优化 > 聚集标签页下可以新建聚集,如下:
示例地址:门店月销汇总表 (opens new window)
- 在
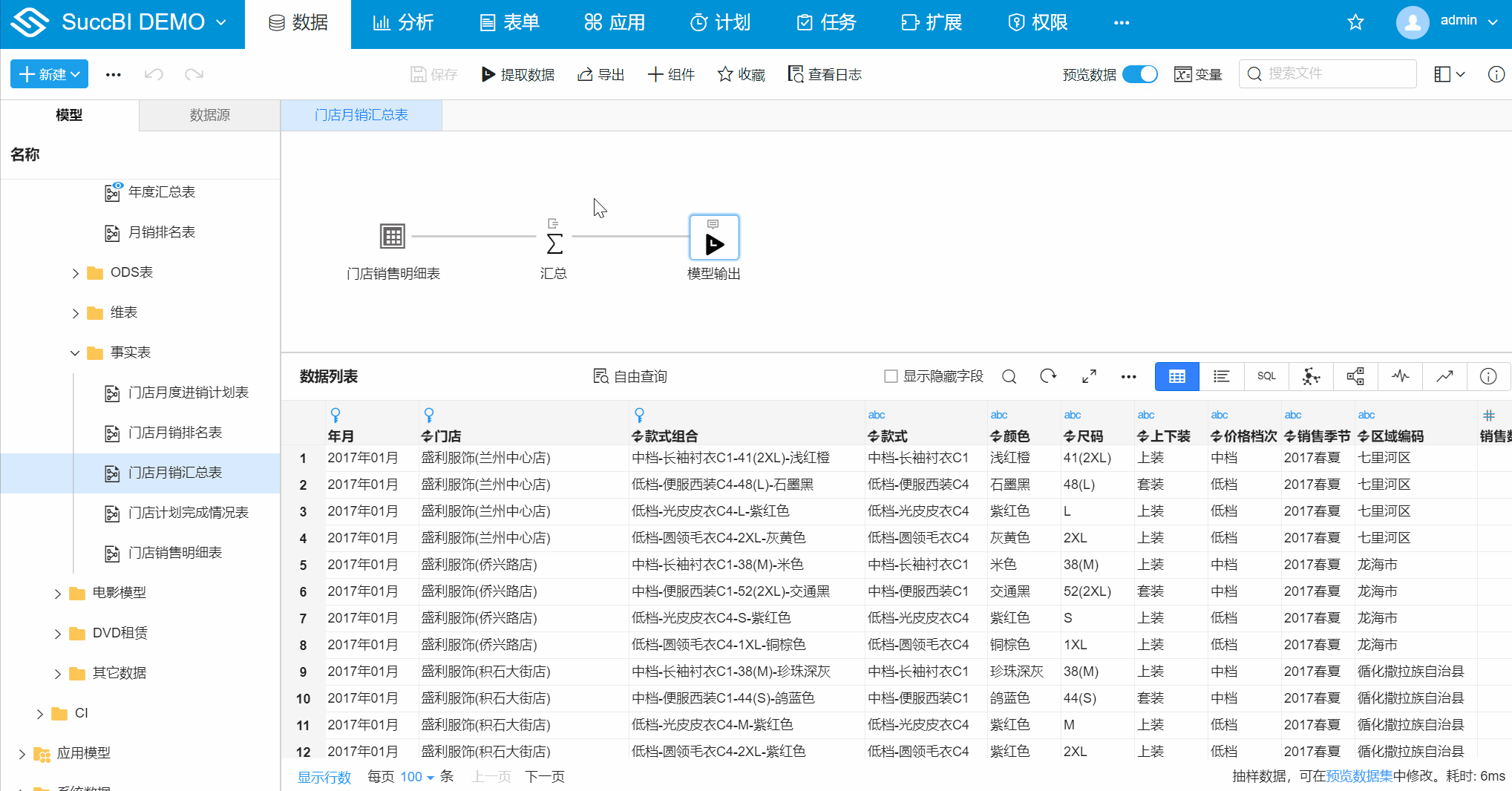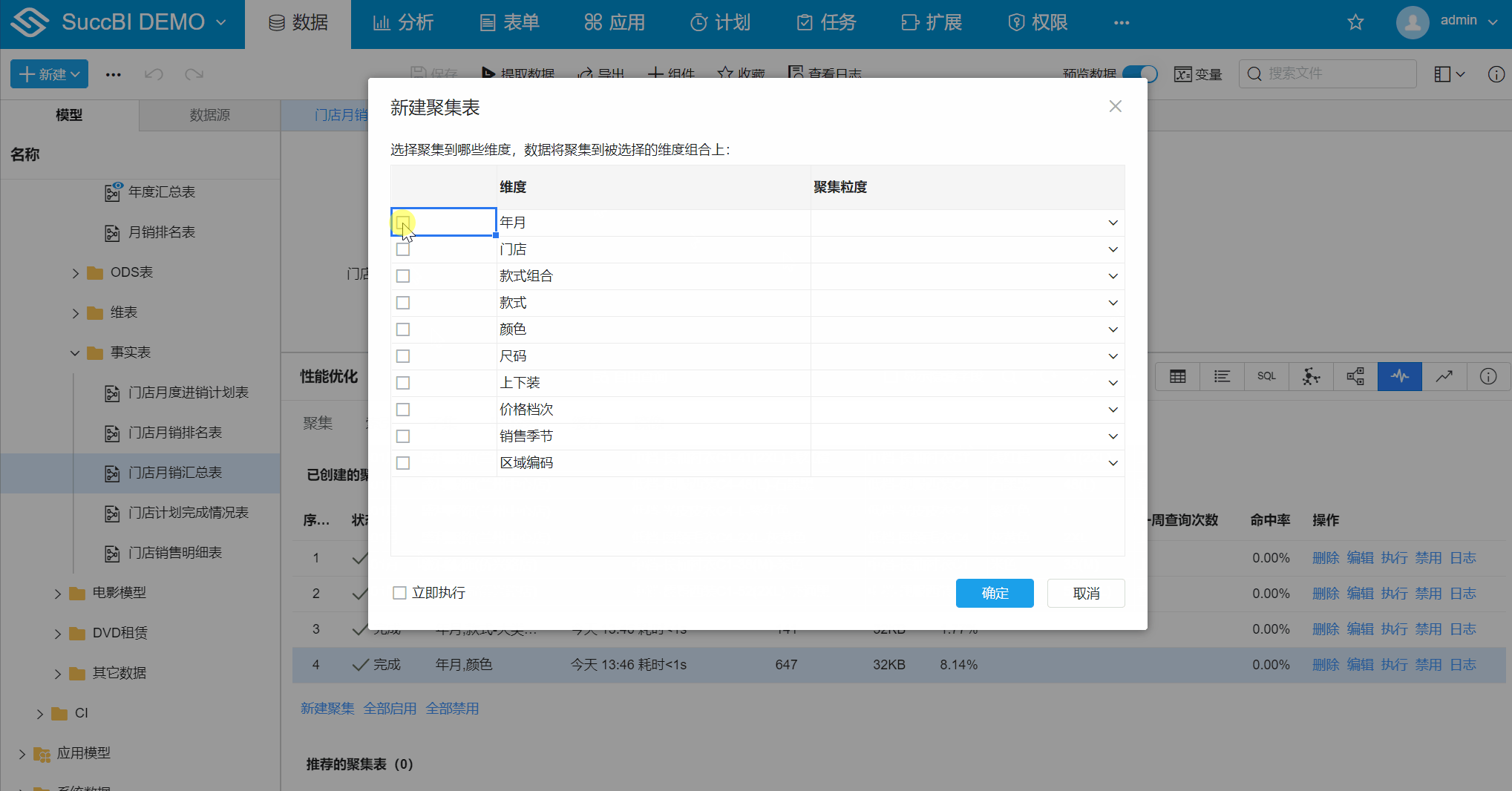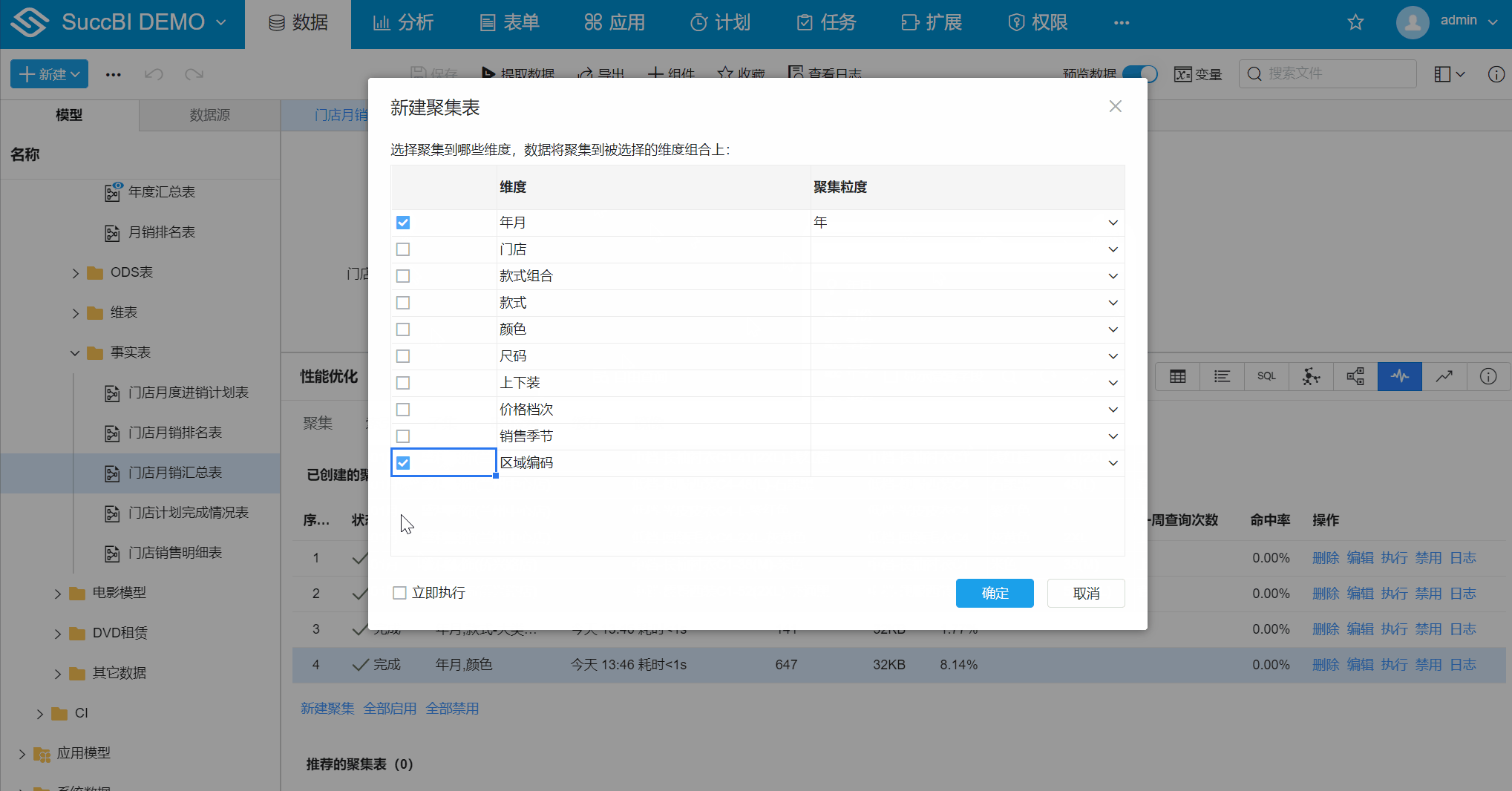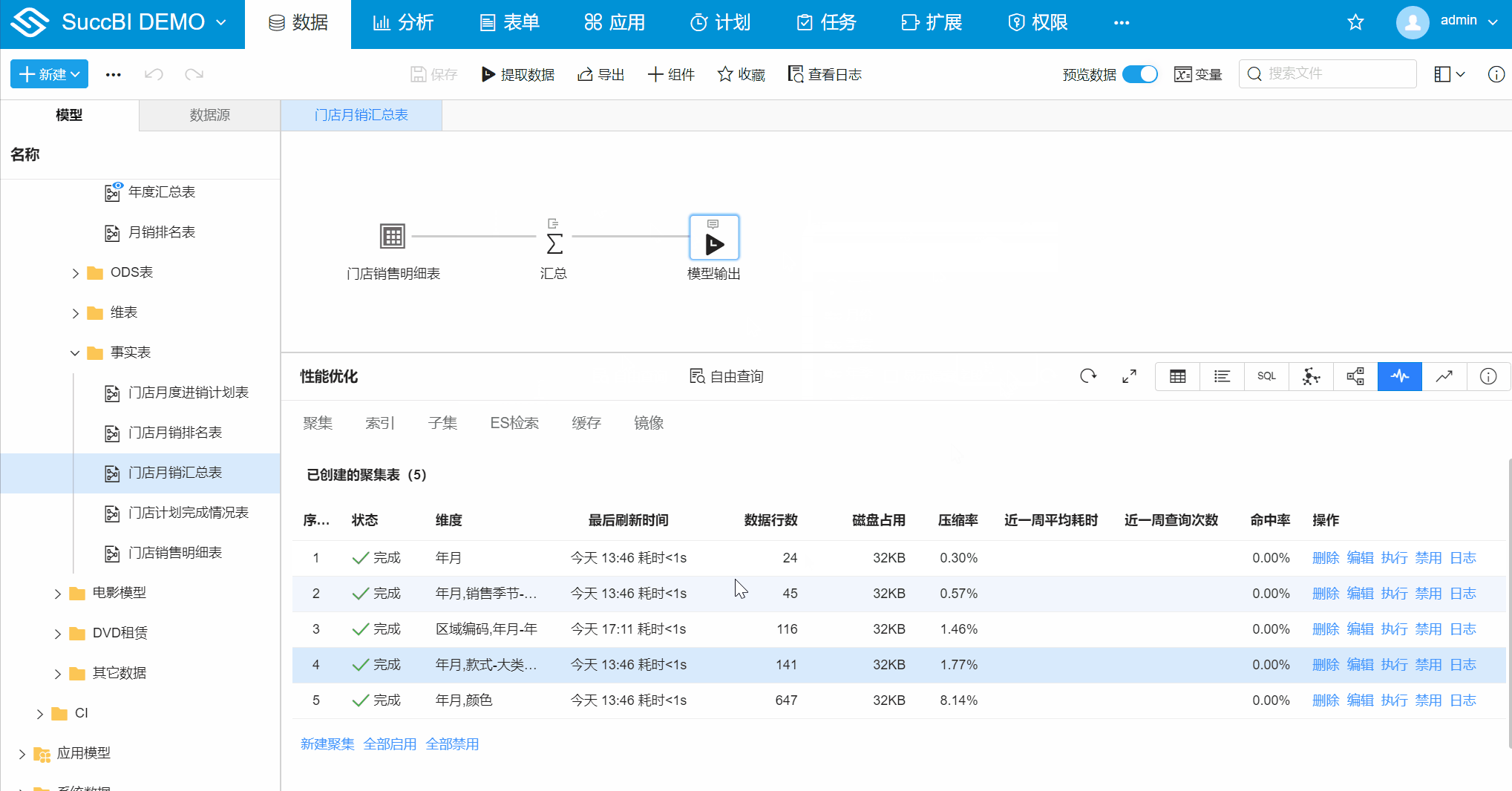
门店月销汇总表中切换至性能优化 > 聚集 - 新建聚集:点击新建聚集,弹出对话框
- 勾选聚集维度:勾选【年月】、【区域编码】,【年月】维度中选择聚集粒度到【年】
- 勾选立即执行:勾选后点击确定
# 聚集列表管理
# 聚集列表属性
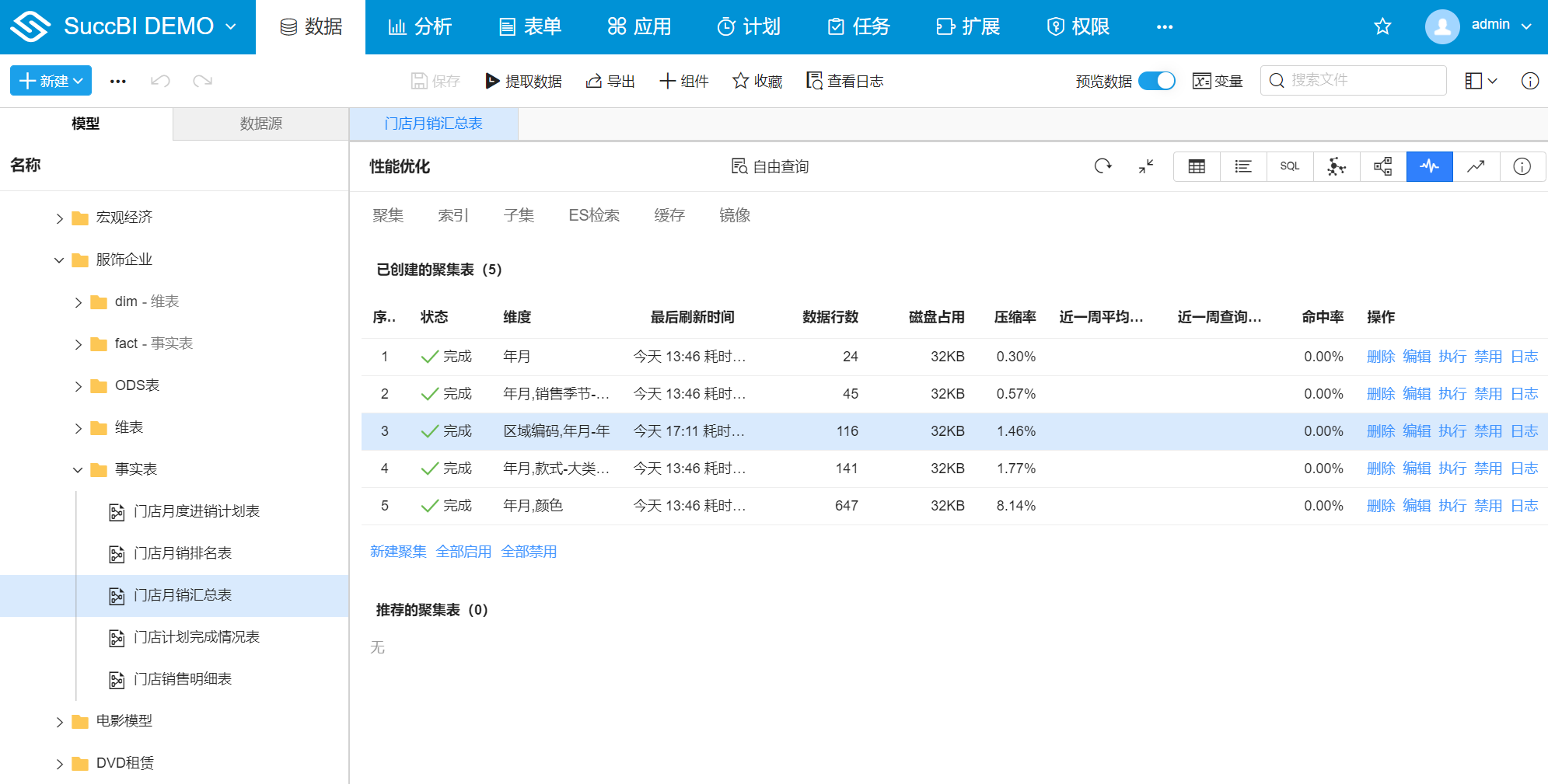
聚集列表展示已经创建的聚集表的信息,具体属性如下:
- 状态:聚集表共有6种状态:
未开始、等待中、执行中,正在刷新、取消中、完成、失败,只有当状态为完成时,聚集表才能被聚集导航使用 - 维度:创建时勾选的维度字段,即聚集表所要聚集到的维度
- 最后刷新时间:最后一次提取的时间
- 数据行数:聚集表中的数据行数
- 磁盘占用:聚集表所占用的磁盘空间大小
- 压缩率:
聚集表行数/原表行数,压缩率越低在查询时性能提升效果越好,建议只创建压缩率在70%以下的聚集表 - 近一周平均耗时:最近一周聚集表提取的平均耗时,暂未实现
- 近一周查询次数:最近一周使用聚集表执行的查询次数,暂未实现
- 命中率:
聚集表被查询总次数/原表被查询总次数,暂未实现 - 操作:
提示
推荐的聚集表功能暂未实现,敬请期待!
# 启用和禁用聚集
可以单个或批量启用和禁用聚集表:
- 单个启用/禁用:在聚集列表的【操作】列中点击启用/禁用按钮来控制对应的聚集表可用状态
- 批量启用/禁用:在聚集列表的下方点击全部启用/全部禁用按钮来批量控制聚集表的可用状态
提示
聚集表被禁用后,在聚集列表中会被置为灰色的不可用状态,聚集导航只能使用已启用的聚集表。
# 执行聚集
聚集表可以通过如下几种方式执行提取:
- 在新建/编辑聚集表的对话框中,勾选立即执行,确定后系统自动执行聚集表的提取
- 手动在聚集列表的【操作】列下点击执行
- 手动执行加工模型提取时,提取完成后在提取对话框的左下角会出现继续提取子表按钮,点击该按钮可以提取性能优化标签页下所有的子表,包括聚集表、子集表等
- 在系统调用管理中执行计划时,加工模型的所有子表包括聚集表也会在加工提取完成后执行一次提取
提示
- 正常完成提取后,聚集表状态会变为
完成 - 加工重新执行提取后,聚集表状态会变为
未开始,也需要重新执行一遍提取,才能被聚集导航正常使用。
# 聚集对话框属性
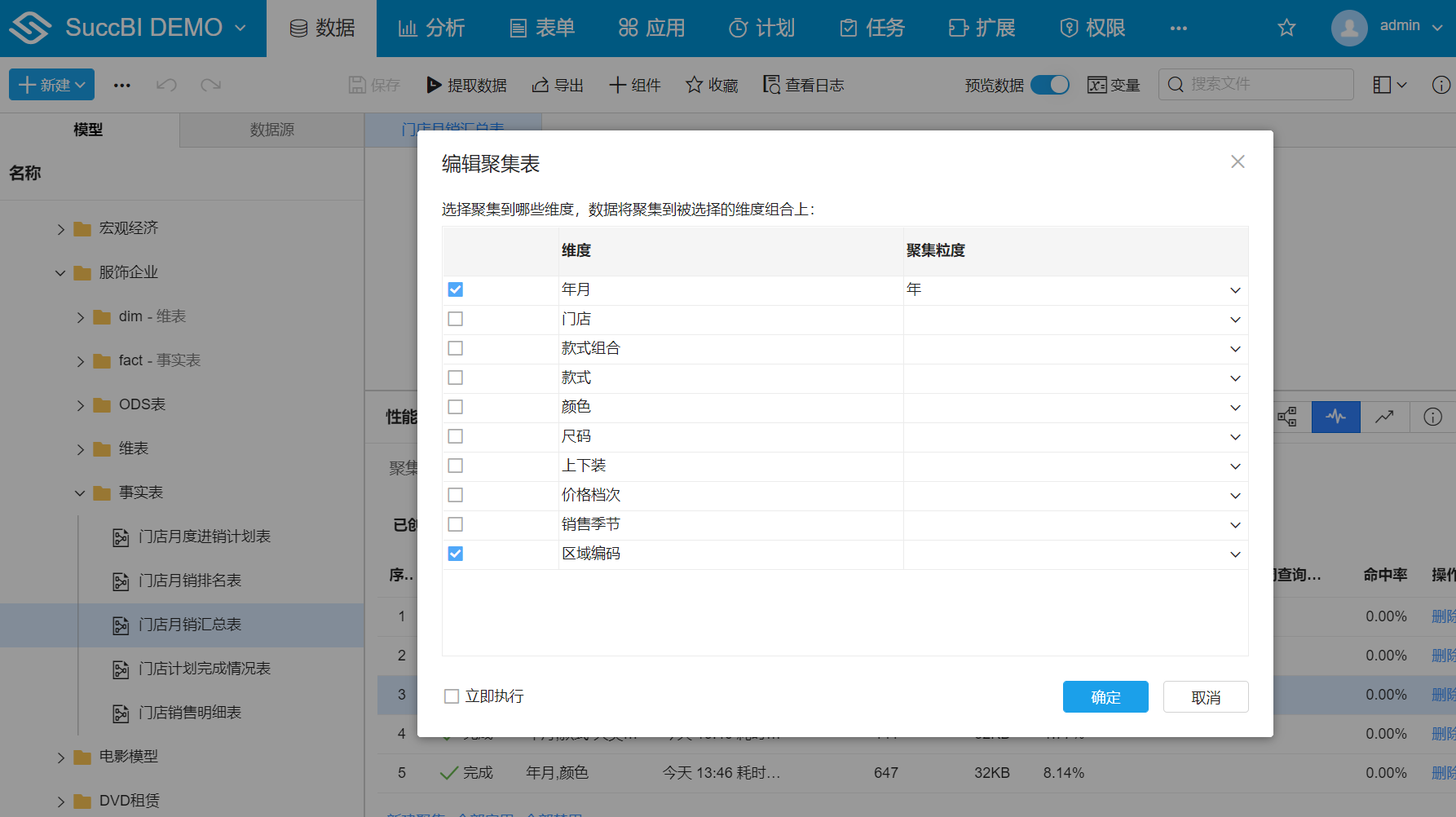
- 维度:可勾选一个或多个模型表中的维度字段
- 聚集粒度:当前字段可能是日期角色或设置了关联表,可选择聚集到关联维表上的某个粒度上
- 立即执行:勾选后,点击确定将自动执行聚集表的提取,并弹出提取日志对话框
# 聚集导航
在数据仓库应用中,通常需要对模型按照不同维度过滤、分组统计,你可以在原始模型的聚集管理中定义多个聚集表以适应不同的查询需求。
SuccBI支持聚集导航功能,即在应用模型的地方使用原始模型来制作,如报表、仪表板等,系统执行查询时能根据所选的维度过滤条件、分组方式在不改变原有输出结果的前提下智能选择聚集粒度最粗、数据量最小的聚集表替代原表查询,以此提升查询效率,整个过程对应用完全透明,无需做任何修改。
提示
为了保证数据的一致性,聚集导航只能使用已启用的、状态为完成的聚集表
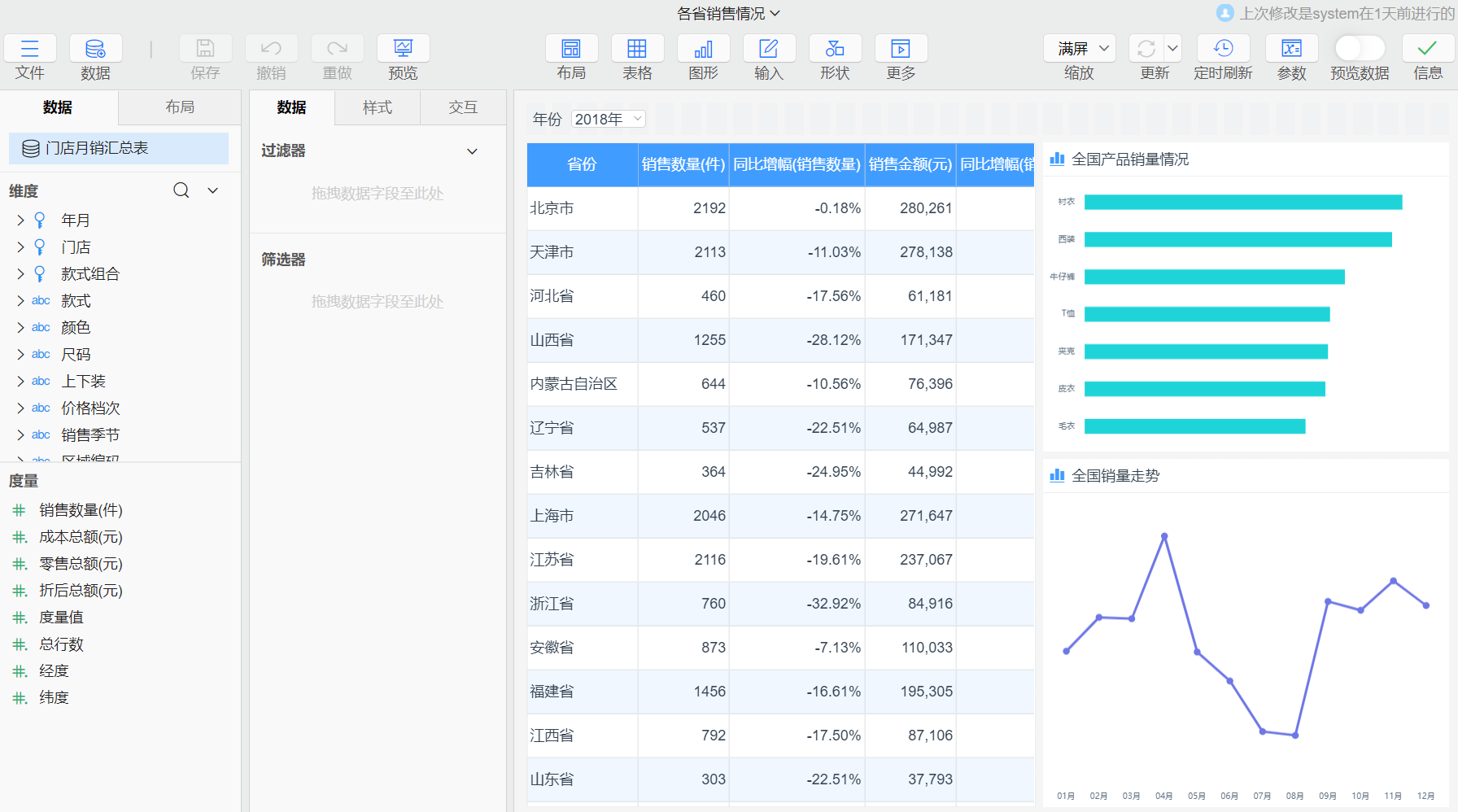
例如,服饰的各省销售情况仪表板基于门店月销汇总表制作,左侧的分组表中使用【年份】过滤,使用【区域编码.省份】分组统计,在门店月销汇总表中创建聚集到【年份】、【区域编码】的聚集表后,将使用该聚集表替代原表查询。
示例地址:各省销售情况 (opens new window)