# 性能优化
在使用数据加工过程中,遇到大数据量表、字段个数过多表、多表关联或复杂加工逻辑等情况时,可能会遇到加工组件使用不流畅、数据刷新时间长等性能问题,导致严重影响自助加工的使用体验,而其中大多数情况是可以通过良好的使用技巧来避免的。
下面介绍下几种能有效提升自助加工体验的使用技巧:
# 预览数据集
数据加工的输入表支持设置预览数据集。预览数据集用来按照某种方式抽样数据,让数据加工的后续制作流程中,数据加工逻辑结果的预览在该抽样数据上进行,用来提升加工使用流畅性,尤其是对涉及到多个大表的复杂加工流程时非常有效。
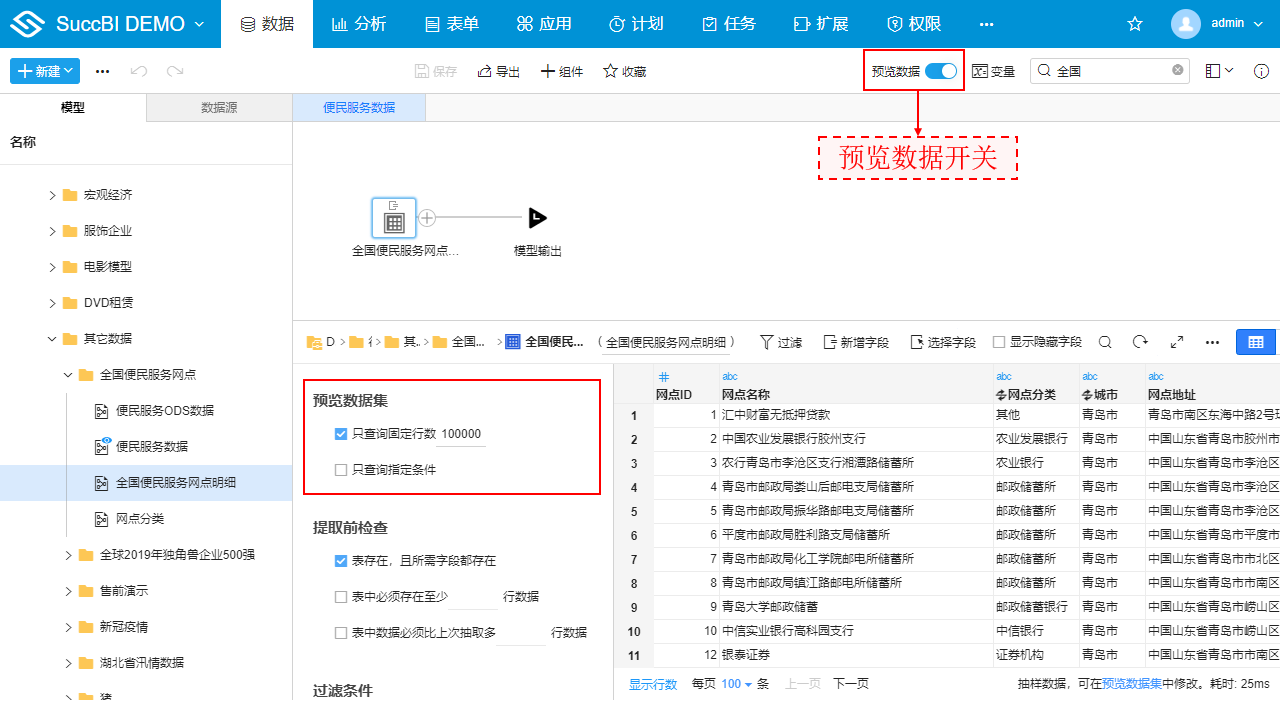
- 预览数据集:预览数据集支持两个方式来抽样数据
- 只查询固定行数: 可设置只查询当前表的前N行,N可以指定,默认为10000
- 只查询指定条件: 可自定义表的过滤条件
- 预览数据开关: 决定本加工内所有输入节点上设置的预览数据集过滤条件是否生效
- 项目设置: 在项目设置中设置默认查询预览数据,初次打开数据加工时会自动开启预览数据开关
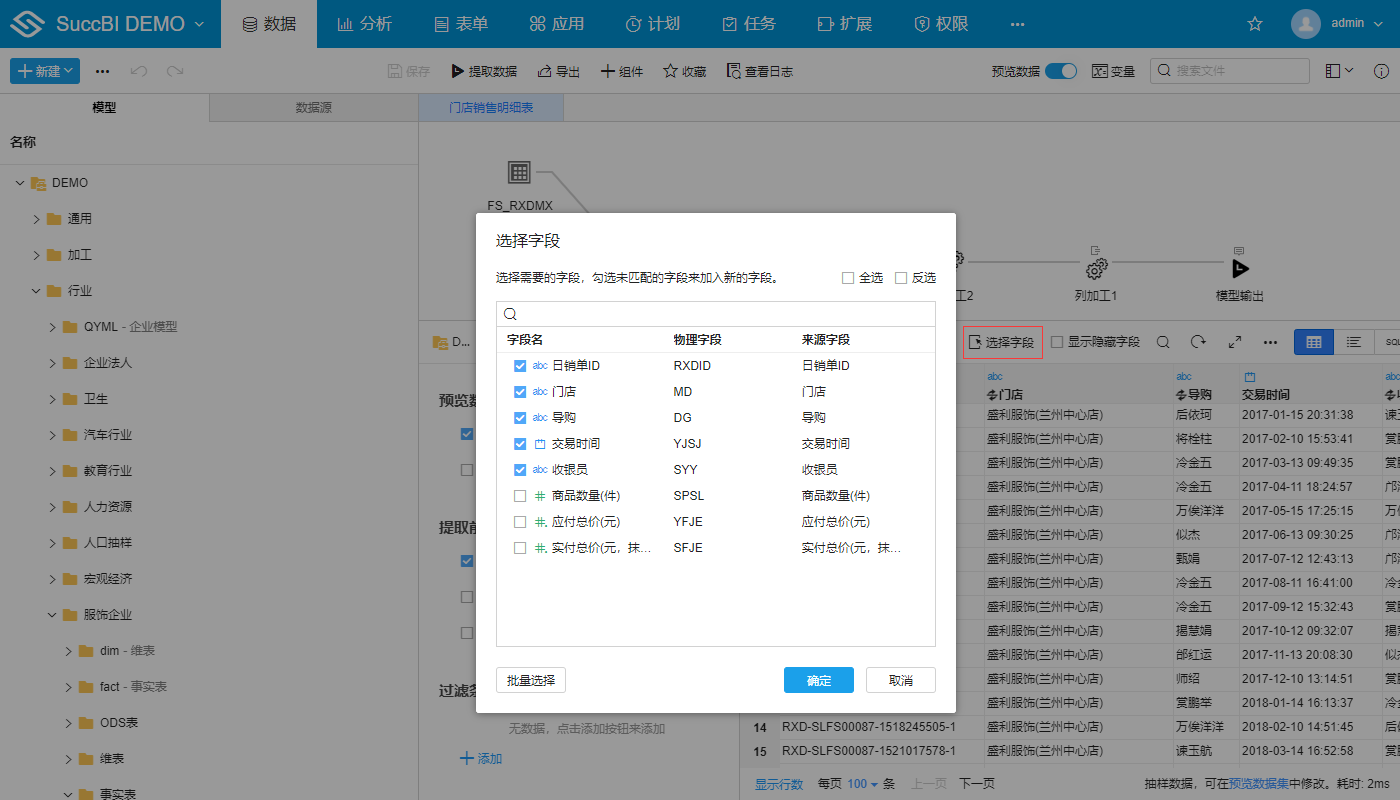
# 去掉不必要的字段
数据仓库中的模型字段个数一般比较多,上百个都是比较常见的。显示过多的字段非常影响数据加工使用的性能,尤其是对于列式数据库,查询不必要的字段带来的性能衰减非常明显。
在输入表模型中可以通过选择字段按钮来勾选只显示必要的字段:
# 减少大表关联个数
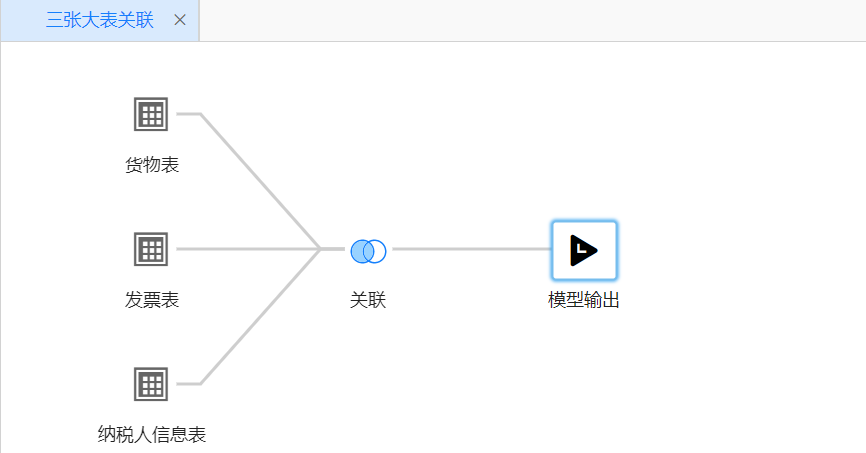
对于Vertica列式数据库,一般超过两个大表的不同字段关联会导致性能低下,且难以优化。加工过程中需要考虑遇到此类情况,尽量建立中间宽表模型来解决,将三张大表的关联,用中间宽表模型转换为两两关联。
- 三张大表的关联
- 创建中间宽表模型
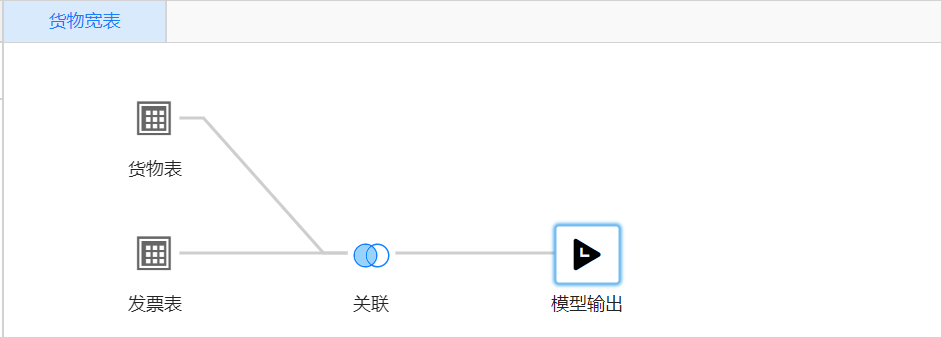
- 转换为两表关联
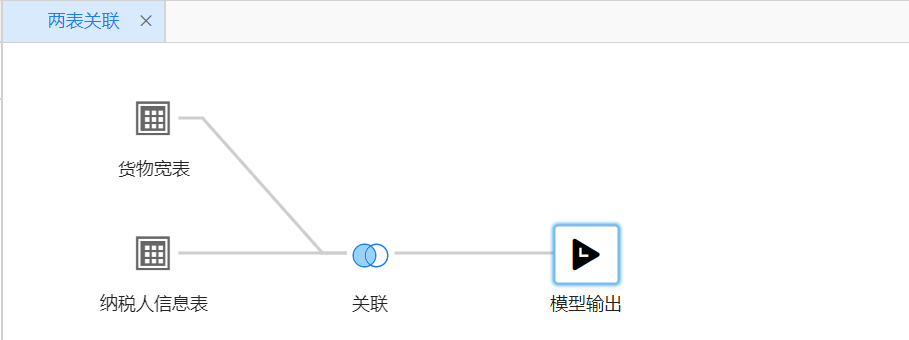
# 提前过滤数据
如果数据加工需要在输入表上过滤数据,则将过滤条件设置尽可能的靠前。对于数据库,部分数据库优化器比较智能能自动将过滤条件下沉,但是也存在数据库的优化器不够智能而无法提前过滤数据,扫描不必要的数据行,导致额外的资源开销。另外,在某些跨源加工中,比如跨源表关联、跨源增量提取,系统会将跨源的表先提取到目标数据源的临时表中再进行处理,如果在跨源提取时能提前过滤数据将能极大提升加工执行性能。
是否有帮助?
0条评论
评论